

Введение
Поиск аномалий во временных рядах является ключевой задачей в анализе данных, особенно в сферах, где непредсказуемые события могут приводить к критическим последствиям, таких как финансы, энергетика и безопасность информационных систем. Например, в 2005 году на нефтеперерабатывающем заводе BP в Техасе произошёл взрыв, унесший жизни 15 человек и ранивший более 170. Расследование показало, что причиной стала утечка газа, которую можно было бы обнаружить с помощью анализа аномалий в данных датчиков. Своевременное выявление отклонений в показаниях могло бы предотвратить трагедию.
Одним из современных подходов является поиск аномалий посредством прогнозирования (anomaly detection by prediction). Такой подход базируется на предположении, что для определения аномалии необходимо два значения: предсказанное моделью значение и пороговое расстояние, превышение которого сигнализирует о возможной аномалии, так как отклонение фактических наблюдений от прогнозируемых значений является индикатором нестандартного поведения временного ряда.
В статье описывается разработанная в нашей компании базовая (Foundation) модель DivergentGPT, которая позволяет искать аномалии во временных рядах на больших объемах данных.
В статье описывается разработанная в нашей компании базовая (Foundation) модель DivergentGPT, которая позволяет искать аномалии во временных рядах на больших объемах данных.
Foundation-модели в прогнозировании временных рядов
В последнее время активно развиваются специализированные foundation-модели для анализа временных рядов, основанные на подходах и архитектурах традиционных foundation-моделей, таких как GPT и BERT, которые изначально создавались для обработки текстовых данных. Эти модели, предварительно обученные на больших объёмах данных, успешно адаптируются для выявления скрытых структур и закономерностей во временных рядах, эффективно перенося знания, полученные при обработке естественного языка, на числовые последовательности. Это позволяет им осуществлять точные прогнозы, формируя одновременно предсказанные значения и определяя пороговые расстояния, после превышения которых наблюдаемые точки временного ряда классифицируются как аномальные.

Рис. 1: Когда прогноз модели встречается с реальностью, разница решает, аномалия это или норма
Традиционные методы прогнозирования временных рядов, такие как ARIMA, экспоненциальное сглаживание и другие, обычно требуют тщательного подбора параметров под конкретный ряд и плохо обобщают свои свойства на новые данные. В отличие от этого, foundation-модели, такие как GPT, обученные на огромном количестве разнообразных данных, способны обобщать знания и адаптироваться к новым временным рядам без значительного дополнительного обучения, что существенно ускоряет и облегчает процесс развертывания в production-среде.
Основным преимуществом использования foundation-моделей является их способность обобщать паттерны на основе множества различных временных рядов. Модель, обученная таким образом, может успешно выявлять аномалии, так как она «видела» разнообразные паттерны и аномальные отклонения, что позволяет ей лучше выделять необычные события по сравнению с узкоспециализированными моделями.
Модель Chronos от Amazon
Одной из foundation-моделей, специально предназначенных для временных рядов, является модель Chronos от компании Amazon. Chronos использует дискретную токенизацию временных рядов, позволяя представлять вещественные значения в виде конечного набора дискретных токенов. Это упрощает процесс обучения и позволяет применять трансформерные архитектуры, изначально разработанные для обработки текстовых данных. Архитектура Chronos основана на трансформерной языковой модели – в ранних версиях использовалась модель типа T5 (Encoder-Decoder).
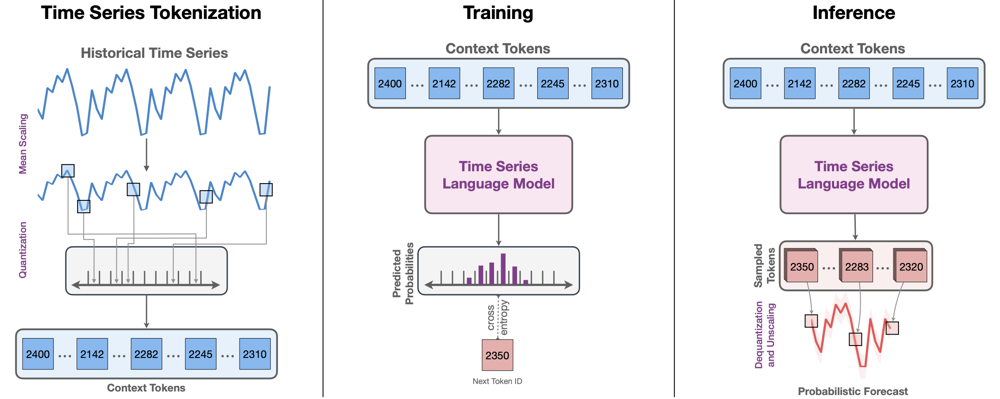
Рис.2: Схема модели Chronos
На рисунке 2 изображена схема модели Chronos. Слева: непрерывный исторический временной ряд нормализуется (mean scaling) и квантуется в дискретные значения, превращаясь в последовательность токенов (целочисленных кодов). Центр: эти токены подаются в трансформер-языковую модель (в случае Chronos использована архитектура T5) и модель обучается предсказывать следующий токен по предыдущим (кросс-энтропийная потеря). Справа: при прогнозировании модель авторегрессионно генерирует последовательность будущих токенов, которые затем обратно преобразуются (деквантование и денормализация) в числовой прогноз с оценкой неопределенности (получая несколько выборок траекторий).
Главная особенность – токенизация входных данных: каждый числовой пункт ряда преобразуется в дискретный токен путем масштабирования и квантования. Проще говоря, значения временного ряда нормализуются (например, вычитанием среднего и делением на масштаб) и округляются до ближайшего уровня из фиксированного набора. В Chronos выбрана довольно высокая разрядность квантования – словарь модели содержит 4096 возможных токенов, что соответствует разбиению непрерывной шкалы на 4096 уровней. После такой дискретизации последовательность токенов обрабатывается трансформером аналогично тексту: модель обучается предсказывать следующий токен по предшествующим (autoregressive modeling) с использованием кросс-энтропии в качестве функции потерь. Для получения вероятностного прогноза запускается множество семплирований будущей траектории– аналогично тому, как языковые модели генерируют разные продолжения текста. Предсказанные токены затем деквантируются обратно в числовые значения, образуя прогнозируемый временной ряд (см. рис. 2, справа). Такой подход позволяет естественным образом получать распределение прогнозов (не только точечную оценку), оценивая неопределенность через разброс сгенерированных траекторий.
Chronos изначально была обучена как foundation-модель: на огромном корпусе различных по природе временных рядов (публичные наборы из разных доменов) и дополнительно на синтетических рядах, сгенерированных при помощи гауссовских процессов. В экспериментах Chronos показала высокую точность предсказаний на новых сериях, превосходя специализированные модели (например, TiDE) в режиме zero-shot (без какой-либо подгонки под конкретный набор). Такой уровень переносимости достигается благодаря обучению на разнообразных доменах (энергетика, транспорт, ритейл, погода, финансы и т.д.) и различных временных разрешениях.
Однако для задач, связанных с обнаружением аномалий во временных рядах, одной только модели типа Chronos может быть недостаточно. Помимо точечного прогноза, необходимо также определить, насколько значительным должно быть отклонение от прогнозируемых значений, чтобы оно считалось аномальным. Обычно для этого используют классические статистические подходы, например, метод стандартного отклонения. Мы же решили развить идеи, заложенные в Chronos, и создать модель, которая бы прогнозировала не только ожидаемые значения временного ряда, но и диапазон их возможных колебаний. Это позволит нам устанавливать адаптивные границы аномальности, учитывающие прогнозируемую неопределённость.
Главная особенность – токенизация входных данных: каждый числовой пункт ряда преобразуется в дискретный токен путем масштабирования и квантования. Проще говоря, значения временного ряда нормализуются (например, вычитанием среднего и делением на масштаб) и округляются до ближайшего уровня из фиксированного набора. В Chronos выбрана довольно высокая разрядность квантования – словарь модели содержит 4096 возможных токенов, что соответствует разбиению непрерывной шкалы на 4096 уровней. После такой дискретизации последовательность токенов обрабатывается трансформером аналогично тексту: модель обучается предсказывать следующий токен по предшествующим (autoregressive modeling) с использованием кросс-энтропии в качестве функции потерь. Для получения вероятностного прогноза запускается множество семплирований будущей траектории– аналогично тому, как языковые модели генерируют разные продолжения текста. Предсказанные токены затем деквантируются обратно в числовые значения, образуя прогнозируемый временной ряд (см. рис. 2, справа). Такой подход позволяет естественным образом получать распределение прогнозов (не только точечную оценку), оценивая неопределенность через разброс сгенерированных траекторий.
Chronos изначально была обучена как foundation-модель: на огромном корпусе различных по природе временных рядов (публичные наборы из разных доменов) и дополнительно на синтетических рядах, сгенерированных при помощи гауссовских процессов. В экспериментах Chronos показала высокую точность предсказаний на новых сериях, превосходя специализированные модели (например, TiDE) в режиме zero-shot (без какой-либо подгонки под конкретный набор). Такой уровень переносимости достигается благодаря обучению на разнообразных доменах (энергетика, транспорт, ритейл, погода, финансы и т.д.) и различных временных разрешениях.
Однако для задач, связанных с обнаружением аномалий во временных рядах, одной только модели типа Chronos может быть недостаточно. Помимо точечного прогноза, необходимо также определить, насколько значительным должно быть отклонение от прогнозируемых значений, чтобы оно считалось аномальным. Обычно для этого используют классические статистические подходы, например, метод стандартного отклонения. Мы же решили развить идеи, заложенные в Chronos, и создать модель, которая бы прогнозировала не только ожидаемые значения временного ряда, но и диапазон их возможных колебаний. Это позволит нам устанавливать адаптивные границы аномальности, учитывающие прогнозируемую неопределённость.
Ключевые идеи, заложенные в модель DivergentGPT
Ключевым этапом при использовании трансформеров для анализа временных рядов является выбор подходящего метода токенизации. Традиционная процесс поиска токенов в LLM (Large Language Models) опирается на частотный анализ текстовых корпусов, где токены ранжируются по частоте их появления в исходном наборе данных. Однако при таком подходе числовые значения теряют естественную упорядоченность и близость друг к другу, что значительно затрудняет для модели понимание числовой природы временных рядов.
В противоположность этому подходу DivergentGPT использует так называемую «упорядоченную токенизацию», аналогичную модели Chronos. В этом методе вещественные значения предварительно упорядочиваются, благодаря чему близкие по значению точки кодируются соседними токенами. Это позволяет сохранять числовую структуру данных и значительно облегчает трансформеру понимание закономерностей, свойственных временным рядам.
В противоположность этому подходу DivergentGPT использует так называемую «упорядоченную токенизацию», аналогичную модели Chronos. В этом методе вещественные значения предварительно упорядочиваются, благодаря чему близкие по значению точки кодируются соседними токенами. Это позволяет сохранять числовую структуру данных и значительно облегчает трансформеру понимание закономерностей, свойственных временным рядам.
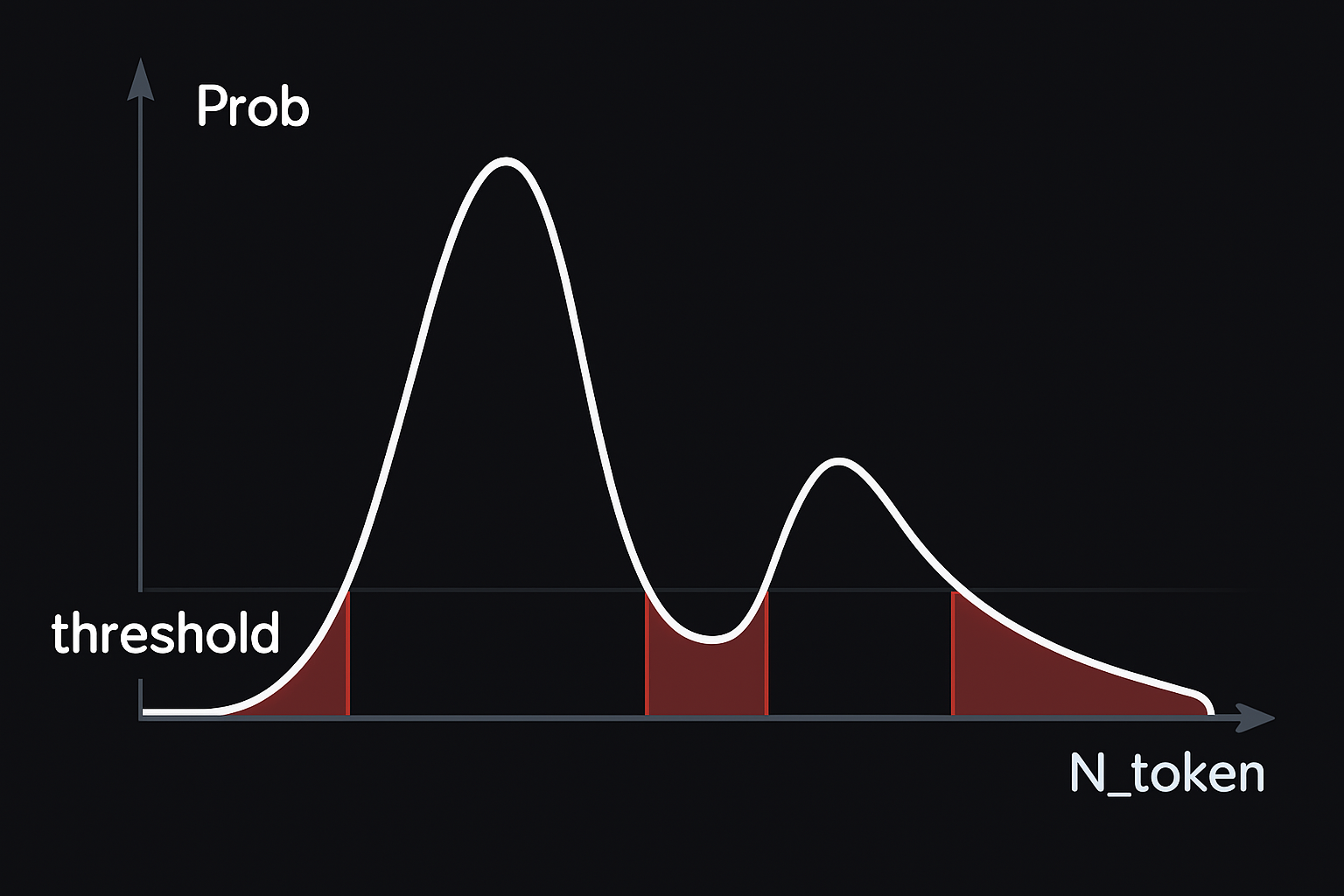
Рис. 3: Ниже порога плотности — территория редких событий, которые модель определяет как аномалии
Использование упорядоченной токенизации лежит в основе ключевых возможностей DivergentGPT. Анализируя разброс вероятностного распределения предсказанных токенов, модель оценивает степень своей уверенности в прогнозе. Помимо предсказания следующего значения временного ряда, DivergentGPT одновременно оценивает границы нормальности значений, реализуя подход anomaly detection by prediction. Если новое наблюдение временного ряда оказывается в зоне токенов с низкой вероятностью, оно классифицируется моделью как потенциальная аномалия.
Дополнительно, благодаря тому, что токены упорядочены, DivergentGPT обучается с использованием комбинированной функции потерь. Наряду со стандартной кросс-энтропийной потерей (cross-entropy loss) используется специальная форма MSE-подобной потери, которая штрафует модель пропорционально удалению предсказанного токена от целевого. В отличие от традиционной кросс-энтропии, где нет разницы между ошибкой на один токен или тысячу токенов, предложенная функция потерь мотивирует модель делать ошибки ближе к истинному значению. Это ведёт к формированию более гладкого и осмысленного распределения вероятностей токенов на выходе.
Ещё одной особенностью токенизации временных рядов является возможность трактовать пропущенные значения (NA) как отдельный токен. Такой токен можно обрабатывать так же, как и любой другой: предсказывать его появление, использовать в контексте для генерации последующих значений и учитывать при моделировании разброса данных.
Обычные foundation‑модели чаще всего ограничиваются точечным прогнозом следующих значений. DivergentGPT же предсказывает событие, выходящее за пределы нормы, и оценивает возможный диапазон отклонения. Благодаря тому, что DivergentGPT является foundation‑моделью, знания, полученные на обучающих данных, переносятся на новые наборы данных, в которых ищутся аномалии. Это означает, что модель может точнее выявлять отклонения в поведении пользователей, работе оборудования или предстоящие колебания финансовых показателей компаний и сразу же показывать вероятный разброс этих изменений
Заключение
В статье описывается разработанная в нашей компании базовая (Foundation) модель DivergentGPT, которая позволяет искать аномалии во временных рядах на больших объемах данных. Потенциально, данная модель может быть интегрирована в существующие продукты компании, такие как Dataplan (Privilege & Behavior Anomaly Detection), Alertix (SIEM) и Infrascope (PAM), где требуется автоматическое выявление отклонений в поведении пользователей, систем и учетных записей. Использование DivergentGPT позволит повысить точность обнаружения инцидентов безопасности за счёт интеллектуального анализа отклонений от типового поведения в реальном времени.
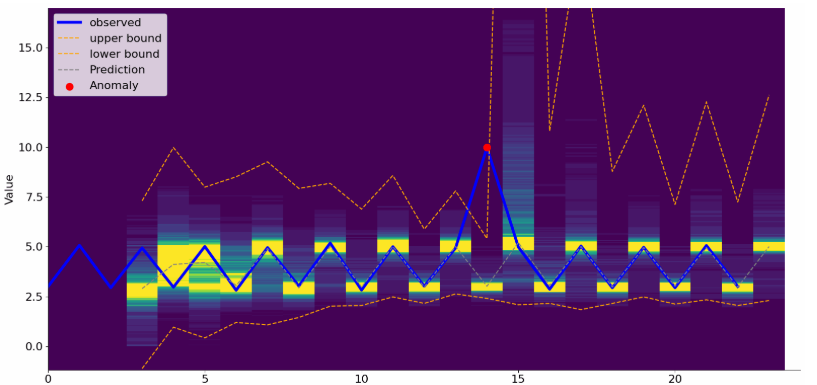
Рис. 4: Пример работы модели на повторяющемся временном ряде с одной аномалией
В следующей части...
В следующей части мы перейдем к практической реализации. Опишем технические решения, применяемые в модели, и параметры, используемые при обучении. Также продемонстрируем производительность модели и покажем, как можно интегрировать такого рода модели в промышленной эксплуатации с временными рядами в Clickhouse.
Автор: Павел Владимиров, эксперт отдела анализа данных NGR Softlab



